
Autor: Kenny Wolf
Die Herausforderung
Bei einem unserer Kundenprojekte kam die Beschwerde auf, dass der Export der Verkaufsdaten zu langsam sei.
Da haben wir uns doch gleich an die Arbeit gemacht und uns die Situation näher angeschaut. Das eigentliche Problem war, dass der Export der Verkaufsdaten länger als 60 Sekunden dauerte. Wie der Zufall das will ist der Server Timeout exakt 60 Sekunden!
Somit war das Ziel die Zeitspanne unter die 60 Sekunden zu bringen.
The Challenger
Unser Software Engineer Lukas von Allmen - aka Lüku - hat sich dieser Challenge angenommen.
Dieser Blog Beitrag wurde aus Lüku's Beer Talk generiert, bei dem er das Vorgehen und die Ergebnisse präsentiert hat.
Situationsanalyse
Erste Herausforderung
Daten. Und zwar sehr viele.
Die Applikation und die User Base ist in den letzten Jahren ziemlich gewachsen. Es sind über 11 Mio. Verkäufe bei ca. 110'000 verschiedenen Kunden. Und über 22 Mio. Submissions von Verkäufen und Kunden.
Mit der Anzahl der Daten ist die Zeitspanne des Exports gestiegen, bis nun ja, der Server "Ne heute nicht" gesagt hat.
Zweite Herausforderung
Wie man nun vermuten kann, ist mit den Jahren ebenfalls die Komplexität der Applikation gestiegen.
Ich will Sie nicht mit Details langweilen. Deshalb habe ich Ihnen hier zwei Grafiken. Die erste spiegelt die Datenbank Tabellen wider, die zweite Grafik zeigt die Django Models an.


Wie weiter?
Um das Ausmass der Herausforderung besser einschätzen zu können, wollten wir zuerst wissen, wie die Zahlen aussehen.
Aus dem Grund haben wir mit Benchmarking gestartet.
Das Setting:
- Benchmarking auf der lokalen Maschine und auf der Stage
- Parameter definieren um Konstanz zu gewährleisten:
- das gleiche Unternehmen für einen Monat
- Verkaufsdaten: 10'000
Dafür mussten wir noch ein Benchmarking Tool aussuchen, das für unseren Zweck dient.
Da gab es einige Optionen, eine davon CProfile. Genauer gesagt die Bibliothek spezifisch für Django - django-cprofile-middleware. Das Programm hält was es verspricht, aber der Output ist nicht wirklich visuell ansprechend und sehr schwer zu lesen (no front).
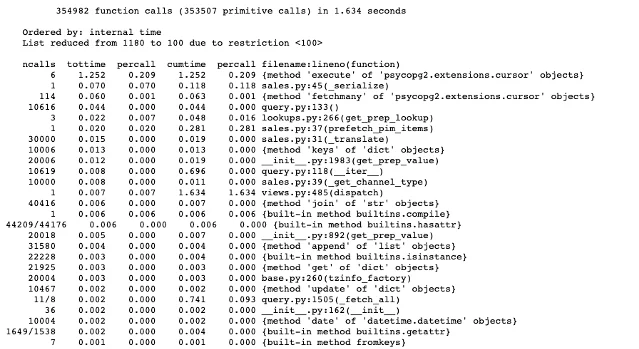
Daraufhin fanden wir ein weiteres Tool, welches die gewünschten Zahlen liefert und übersichtlich ist - Snakeviz.
Nun ja, übersichtlich ist vielleicht nicht das richtige Wort, aber damit kann man wenigsten arbeiten. Ein nützliches Feature von Snakeviz, welches wir brauchten, ist die Baum Hierarchie. Dadurch konnten wir genau sehen, wo welche Queries wie viel Zeit beanspruchten.
Allerdings war es nötig sich durch die Hierarchie zu kämpfen und etwas Ausprobieren, um zu sehen wo genau der Ursprung war, an dem viel Zeit beansprucht wurde.
Benchmarking
Nun zum eigentlichen Benchmarking.
Dabei wurden mindestens je 3 Läufe gemacht auf der lokalen Umgebung und auf der Stage. Aus den Daten wurden folgende Zahlen interpretiert:
- Lokal: Die Request time (also Zeit der Anfrage) liegt bei > 5 Sekunden
- Stage: Die Request time (also Zeit der Anfrage) liegt bei > 14 Sekunden
I am speed
Da nun ein Gesamtbild der Situation geschaffen wurde, konnte man sich endlich an die Arbeit machen und eine Lösung suchen.
Eine dieser Lösungen war Serpy Serializer. Serpy ist ein einfaches Framework zur Objektserialisierung, welches auf Geschwindigkeit ausgelegt ist.
Die Vor- & Nachteile von Serpy:
Pros:
- Es ist schneller, da es ein kleineres Framework ist und somit "lightweight"
- Drop-in replacement - ist gut mit aktuellem Code ersetzbar
- Erwähnungen als Alternative von DRF selber
Cons:
- Neues Framework: kein Wissen vorhanden
Eine weitere radikale und doch pragmatische Lösung ist: einen eigenen Serializer zu bauen.
Das heisst, von Grund auf selber programmieren, ohne Framework oder Bibliothek. Dabei fällt der ganze Source Code weg, den bei Frameworks geladen wird. Dies macht es viel leichter.
Die Vor- & Nachteile von Eigenbau:
Pros:
- Noch schneller als Serpy
Nachteile:
- Entwicklungszeit - von Grund auf selber bauen heisst auch, dass mehr Zeit dafür gebraucht wird
Da Zeit und Budget vorhanden waren, wurde die Entscheidung getroffen, den Serializer selber zu bauen. Ausserdem waren wir der Einschätzung, dass ein eigener Serializer schneller sein wird als der von Serpy. Da keine Verknüpfungen zu anderen Klassen und Methoden geladen werden, die es nicht braucht.
Die Stunde der Wahrheit
Nach der Implementierung des eigenen Serializers waren wir gespannt auf das Benchmarking.
Das Setting war wieder das selbe wie beim Benchmarking der vorherigen Situation. Davor hatten wir über 6 Sekunden für eine Anfrage.
Und nun:
- Lokal: Die Request time (also Zeit der Anfrage) liegt bei < 1 Sekunde
- Stage: Die Request time (also Zeit der Anfrage) liegt bei < 2 Sekunden
Was für ein Ergebnis!
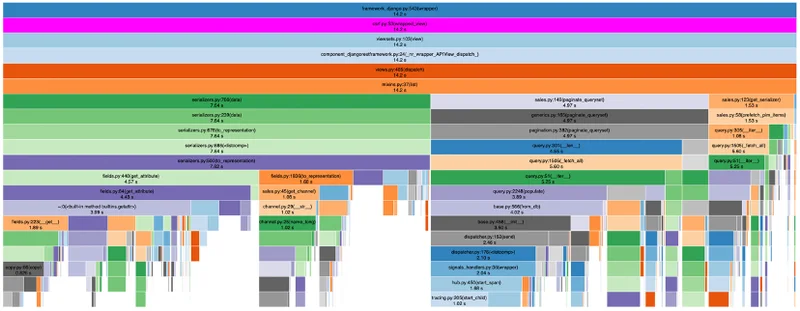
Um das noch visuell zu haben, zeige ich Ihnen noch die Grafiken von Snakeviz. Achten Sie auf den obersten Balken. In einem orangen Rechteck eingezeichnet, finden Sie die Gesamtzeit des Serializers.
Vorher

Nachher

Fazit
Wie Sie vielleicht erahnen, konnten wir auch auf der Produktion ähnliche Ergebnisse erzielen.
Somit haben wir das Ziel, unter 60 Sekunden zu bleiben, gut erreicht. Fazit ist, dass wenn Schnelligkeit ein Faktor ist, man den Serializer selber bauen sollte.
Aber so einfach ist die Antwort nicht.
In unserem Fall hat sich diese Möglichkeit geboten, da unsere Applikation zwar gross war, aber nicht riesig. Bei einem grösseren Export mit noch mehr Daten, Modellen und Datenbanktabellen wäre der Aufwand sehr gross. Dafür müsste das Entwicklerteam über genug Ressourcen verfügen um dies zu bewerkstelligen.
In einem Satz heisst das, dass Sie stets abwägen müssen, ob genügend Ressourcen vorhanden sind und ob sich der Aufwand für diesen Ertrag lohnt.
Schon mal einen Serializer programmiert? Smartfactory entwickelt mit Herzblut und Sachverstand Software. Am Firmensitz in Biel setzen wir für namhafte Grossunternehmen und KMU in der ganzen Schweiz spannende Projekte um.
We're hiring - Unsere offene Stellen
Leseratte? Hier haben wir noch weitere spannende Artikel von unserem Redaktionsteam:
ISO 9001:2015 and me - it's complicated...
Wann und wie eine neue Software für das Unternehmen entwickeln